Spaces and other special characters in the column names in Theobald Bex Query Extract cause errors in Azure Synapse Analytics during loading into a data warehouse.
We worked on a requirement where Theobald job extracted Bex Query Result into a Parquet* file and placed it in the Azure Data Lake Gen2 Container. From Azure Data Lake Storage (ADLS) Gen2 Container, Azure Synapse Pipeline picks up the parquet file and loads it into the Synapse Table.
Parquet: Apache Parquet is an open-source, column-oriented data file format designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk. Apache Parquet is designed to be a common interchange format for both batch and interactive workloads. It is similar to other columnar-storage file formats available in Hadoop, namely RCFile and ORC.
Advantages of Storing Data in a Columnar Format:
- Columnar storage like Apache Parquet is designed to bring efficiency compared to row-based files like CSV. When querying, columnar storage you can skip over the non-relevant data very quickly. As a result, aggregation queries are less time-consuming compared to row-oriented databases. This way of storage has translated into hardware savings and minimized latency for accessing data.
- Apache Parquet is built from the ground up. Hence it can support advanced nested data structures. The layout of Parquet data files is optimized for queries that process large volumes of data, in the gigabyte range for each individual file.
- Parquet is built to support flexible compression options and efficient encoding schemes. As the data type for each column is quite similar, the compression of each column is straightforward (which makes queries even faster). Data can be compressed by using one of the several codecs available; as a result, different data files can be compressed differently.
- Apache Parquet works best with interactive and serverless technologies like AWS Athena, Amazon Redshift Spectrum, Google BigQuery, and Google Dataproc.
Difference between Parquet and a CSV
CSV is a simple and common format that is used by many tools such as Excel, Google Sheets, and numerous others. Even though CSV files are the default format for data processing pipelines it has some disadvantages:
- Amazon Athena and Spectrum will charge based on the amount of data scanned per query.
- Google and Amazon will charge you according to the amount of data stored on GS/S3.
- Google Dataproc charges are time-based.
Parquet has helped its users reduce storage requirements by at least one-third on large datasets, in addition, it greatly improved scan and deserialization time, hence the overall costs.
The following table compares the savings as well as the speedup obtained by converting data into Parquet from CSV.
| Dataset | Size on Amazon S3 | Query Run Time | Data Scanned | Cost |
| Data stored as CSV files | 1 TB | 236 seconds | 1.15 TB | $5.75 |
| Data stored in Apache Parquet Format | 130 GB | 6.78 seconds | 2.51 GB | $0.01 |
| Savings | 87% less when using Parquet | 34x faster | 99% less data scanned | 99.7% savings |
If spaces, or special characters such as “(“or “)” are present in the column names in the Bex query, or the result that generates a parquet file. The file throws an error in Azure Synapse pipeline Data Preview of the Data Flow Activity which is used to load the data synapse table.
For example:
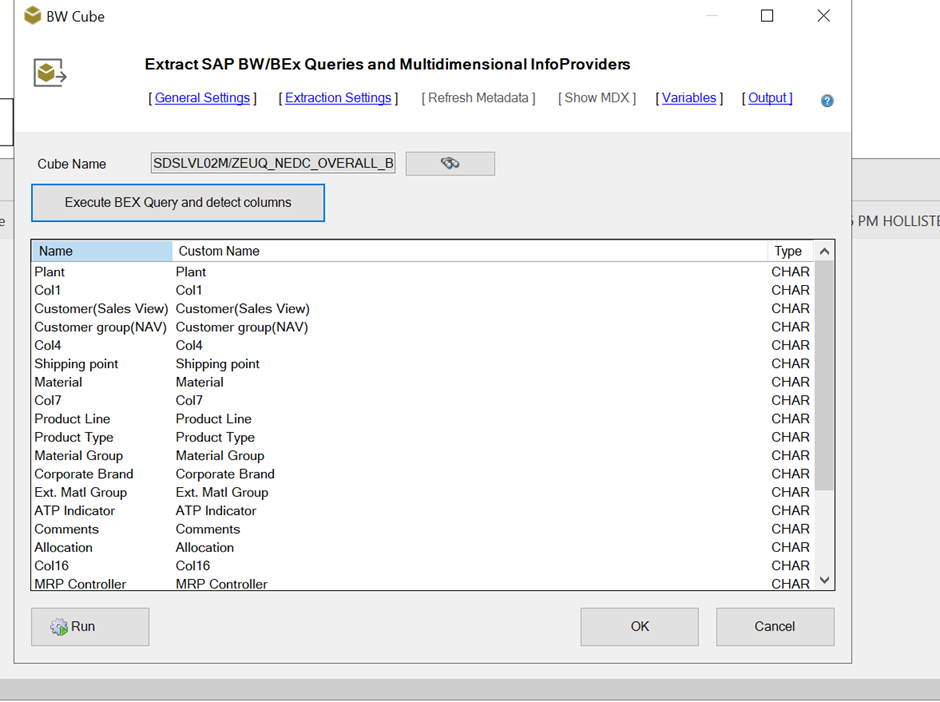
The above screenshot is from Theobald and is seen while we input the query in cube name to search and select. When we click to Execute BEX Query and detect the columns button that shows the query result.
The columns get populated when we close the query result dialog box.
Under Custom Name, we see column names that have multiple strings, separated by a space or enclosed in parenthesis.
There is an option to see Data Preview in Synapse Pipeline Data Flow activity.
For example: Pipeline name = PL_EDW_Backorder_Comment_To_HollisterDW
Error:
execute, tree: Exchange SinglePartition, [id=#44] +- *(1) LocalLimit 1000 +- *(1) FileScan parquet [Plant#461,Material#462,Col2#463,Product Line#464,Product Type#465,Material Group#466,Corporate Brand#467,Ext. Matl Group#468,MRP controller#469,Col9#470,Proj ATP Date#471,Available To Promise#472,Comments#473,Allocation#474,Base Unit#475,BO Quantity in BUM#476,BO Value#477,OHI in BUM#478,Transit In BUM#479,Days on Backorder#480] Batched: true, Format: Parquet, Location: InMemoryFileIndex[abfss://[email protected]/Landing/FTP/SLBO/…, PartitionFilters: [], PushedFilters: [], ReadSchema: struct<Plant:string,Material:string,Col2:string,Product Line:string,Product Type:string,Material …
In the source tab, while previewing the data we encounter the above error.
Taking a closer look at the Bex Query in Theobald, we see there exists spaces, dot(“.”), and special characters like string enclosed in parenthesis.
Unless we fix these errors, the data will not get loaded into the synapse table.
The Solution Provided:
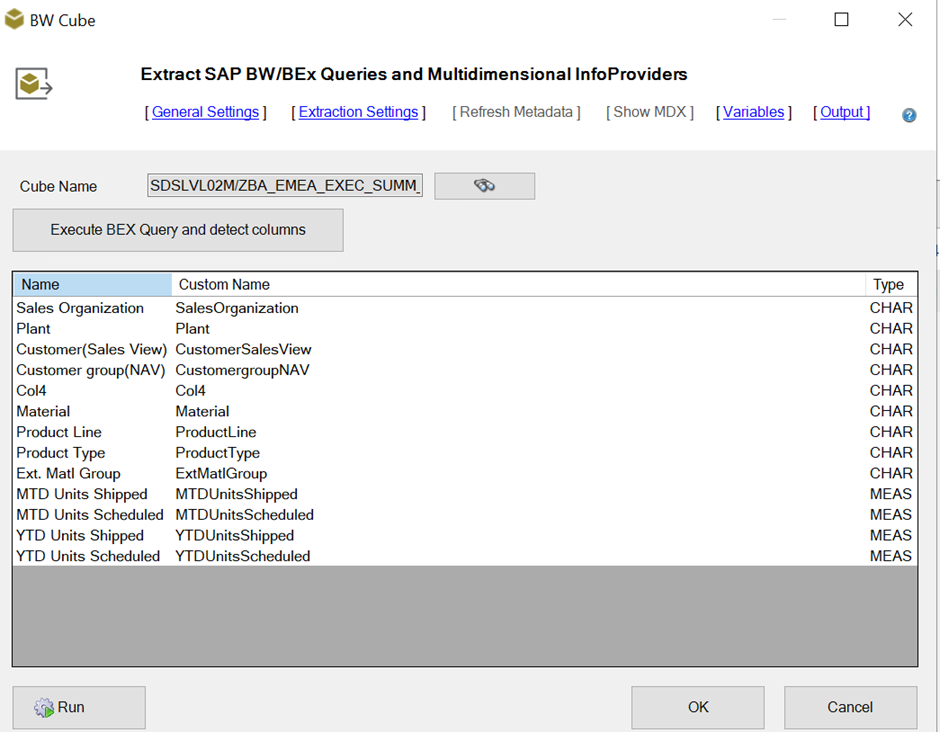
To resolve the problem, we removed the spaces, special characters if any in the Custom Name of the Bex Query so that all the characters in the Column Name are placed continuously without spaces or any other character, before running the job. Running this job will place the parquet file with column names having no spaces or any other characters in the ADLS Gen2 location. Below screenshot shows how the column name should be:
In the Data Flow activity in the Azure Synapse pipeline, we can preview the incoming file. The error will be resolved:
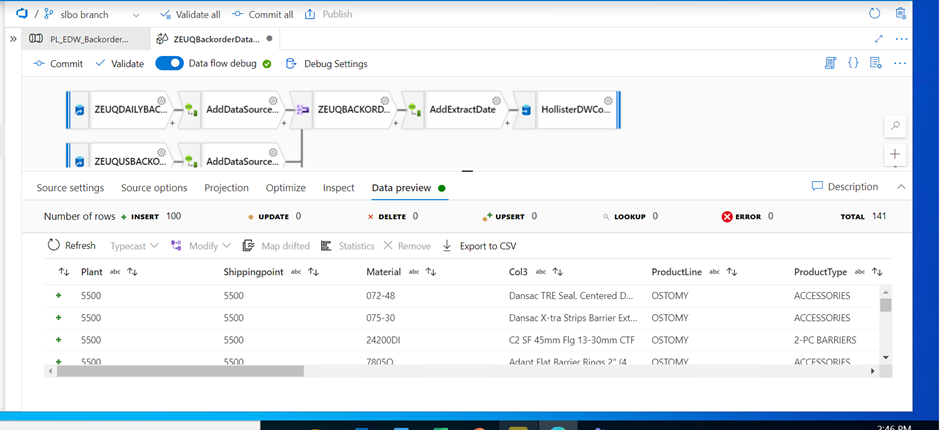
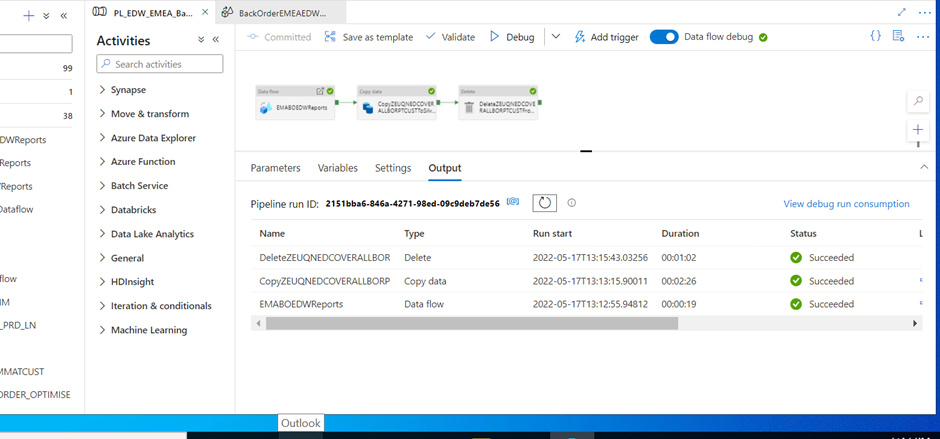
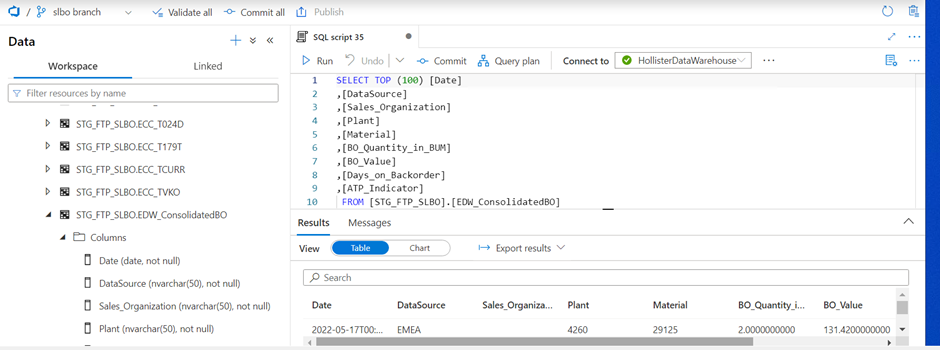
We can see that data is loaded into the synapse table.
Table name = STG_FTP_SLBO.ConsolidatedBO
The solution in this blog will help correct the column name definitions.






