How ‘condition’ characteristic can be useful in the “Distribution By Reference Data” planning function?
I had been working on a requirement to distribute the revenue recognized in a month to all the months in which the cost incurred in order to generate the respective revenue.
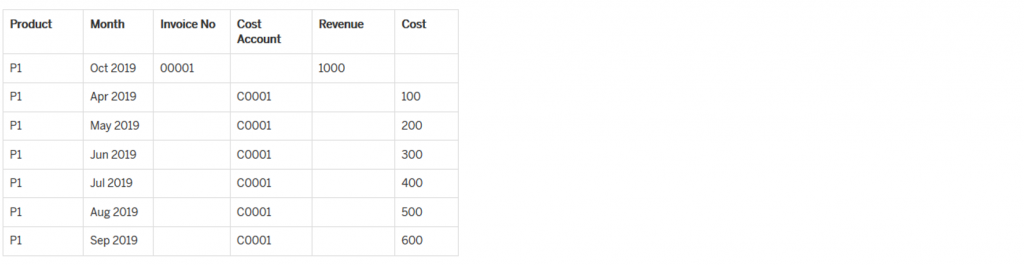
For example; if I have received the payment on an invoice in Oct 2019 but the product was being built from the past 6 months and the cost was recognized every month then revenue should be distributed from Oct 2019 to the past 6 months based on cost recognized in each month.
The above example is better explained in the below table.
Before Distribution
After Distribution
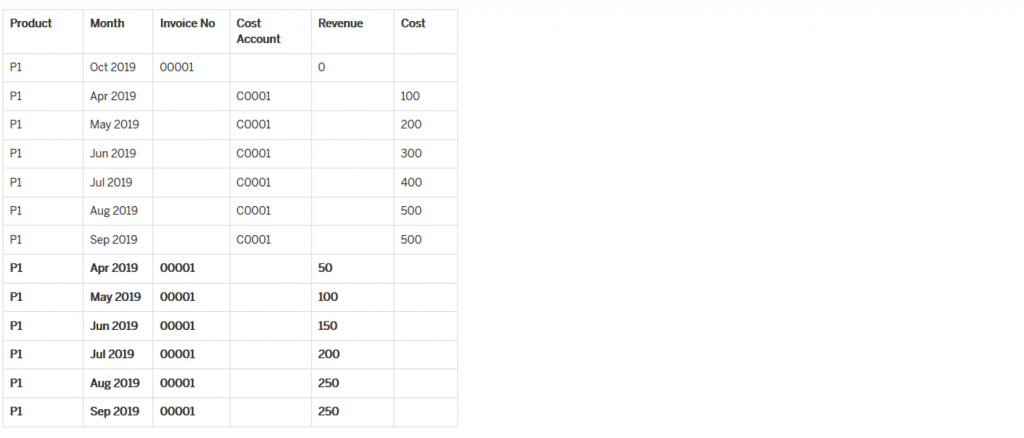
We used the BW Integrated Planning function called “Distribution By Reference Data” which is delivered by SAP as a standard function.
We configured Product as matching characteristic and rest all characteristic remained as ‘Fields to Be Changed’. The key figure to be distributed was Revenue and the Reference Key Figure was Cost.
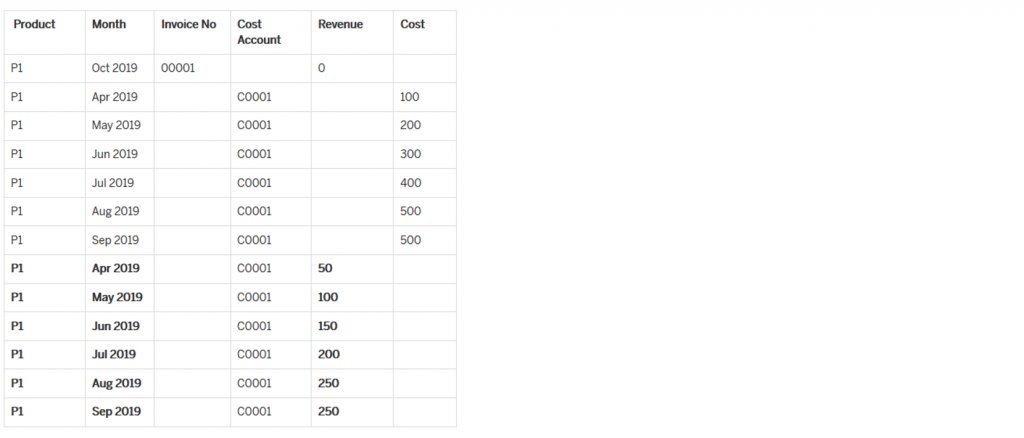
The challenge we were facing here was that the Invoice No was coming blank and Cost Account was getting filled in in the distributed set as shown below.
In order to overcome this; we kept Invoice No. and Cost Account as ‘Condition Characteristic’. Because if we keep them as ‘Fields To Be Changed’ then they take the value from Reference data set which is Cost Account data in this case.
Now, as soon as we convert Invoice No and Cost Account into ‘Condition Characteristic’; they become matching characteristics to reference data set i.e. reference data set must match the characteristic values from the record to be distributed. However, the record to be distributed was having Cost Account = BLANK and Invoice No. = ‘00001’. Therefore, it was not matching with the reference data set and hence it was not distributing anything.
Finally, we found that the matching criteria for ‘Condition Characteristic’ can be overridden in the ‘Reference Data Selection’. Hence, we put a condition in the ‘Reference Data Selection’ as follows;
Invoice No. = #,
Cost Account Excl. #
By doing the above configuration, the function was absolutely working fine.
RESULT
‘Condition Characteristic’ can not only be used for defining conditions on input data set but also for reference data set in order to retain the original characteristic value post distribution.

Pankaj Agrawal







