The modern business world is demanding fast deployment of data insights. Companies need efficient methods to transition from data collection to analytics, AI, and machine learning.
Conventional ETL (extract, transform, load) frameworks often fail to meet the technical demands of big data and real-time analysis. To tackle these challenges, a new data management approach known as Zero-ETL has been developed, designed to reduce or eliminate the reliance on traditional ETL processes.
Understanding Zero-ETL: What It Is and How It Works
Zero-ETL significantly minimizes or removes the need for conventional ETL pipelines. It enables queries across different data sources without relocating the data, streamlining processing, and improving efficiency.
Unveiled at the Amazon Redshift conference in 2022, Zero-ETL was launched alongside the integration of Amazon Aurora with Amazon Redshift. AWS has subsequently created services allowing direct data analysis and transformation within data platforms, eliminating the need for separate ETL processes.
In a conventional ETL pipeline, data experts pull data from various sources such as databases, APIs, JSON files, or XML files.
Once extracted, the data is transformed through integration, calculations, table merging, and eliminating redundant information.
Finally, the processed data is moved to a platform for detailed analysis, which may include machine learning, statistical assessments, or data visualization. This process is complex and requires significant time, cost, and effort.

Let us take an example. Traditional ETL processes are like cooking a meal from scratch. You start by gathering all the ingredients (data extraction), then prepare and cook them (transformation), and finally, plate the meal and serve it (loading). Now, consider a meal delivery service where the meal arrives fully prepared and ready to eat or a buffet where everything is already set up and ready for immediate consumption.
Similarly, Zero-ETL transforms data processing by eliminating the need for extraction, transformation, and loading. This approach minimizes data movement and enables data transformation and analysis within a single platform.
Zero-ETL provides real-time or low-latency data analytics, which benefits data scientists and business stakeholders.
What is the operational mechanism of Zero-ETL?
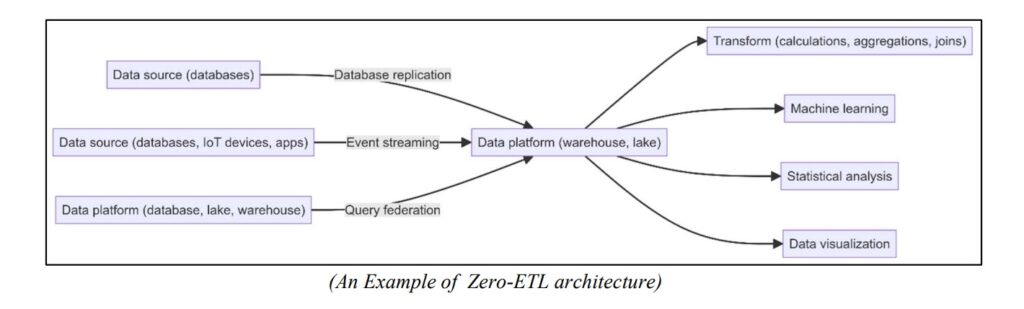
Zero-ETL simplifies data integration by linking data sources directly to data warehouses or lakes, ensuring that real-time data is immediately available for analytics and reporting. This capability utilizes diverse cloud-based technologies and services, including:
Database replication
Database replication entails duplicating and synchronizing data from one database to another.
In zero-ETL, connecting a database and a data warehouse, replication guarantees that the data in the data warehouse remains automatically updated in real-time or near real-time. This integration eliminates the need for separate ETL procedures, as exemplified by the linkage between Amazon Aurora and Amazon Redshift.
Unified Querying/ Federated querying
Federated querying allows for querying data across multiple sources, such as databases, data warehouses, or data lakes, without centralizing the data in one place.
In a zero-ETL context, federated querying empowers data experts to access and analyze data from various platforms directly. This approach provides a unified data view without the complexities associated with traditional ETL operations.
Data streaming
Data streaming involves the ongoing processing and immediate transmission of data as it is produced in real time.
Within zero-ETL frameworks, data streaming encompasses capturing data from diverse sources like databases, IoT devices, or applications and swiftly delivering it to a data warehouse or data lake. This method ensures rapid data availability for analysis and querying, sidestepping the necessity for batch ETL processes.
In-place data analytics
In-place data analytics integrates critical transformations directly within the cloud data platform, such as a data lake. This setup facilitates immediate data processing and analysis at its storage location, reducing latency and improving operational efficiency.
Picture a library where books are read and analyzed on the spot, utilizing advanced technologies that interpret the content of each book without requiring them to be moved to another section for sorting or assessment. This eliminates the need for additional steps in organizing the library for readers.
Common Use-Case Scenarios for Zero-ETL
Instant Data Insights: Zero-ETL eliminates the need for traditional batch ETL by providing instant access to newly generated data, including customer interactions, user behaviours, and vehicle traffic patterns. This automation empowers teams to make rapid data-driven decisions, improving responsiveness and operational efficiency.
Immediate Data Transfer: In a zero-ETL data management framework, eliminating the ETL pipeline accelerates or achieves real-time data replication to another warehouse, ensuring expedited access for data scientists.
Machine learning and AI: Zero-ETL offers significant advantages for machine learning and AI applications by ensuring rapid data access, a critical requirement for these tasks. By facilitating real-time data streaming and instant availability, it supports continuous training and updating machine learning models using the most current data, improving the precision and relevance of AI predictions and insights.
Advantages of zero-ETL
Zero-ETL offers several benefits to data management and analytics:
Simplified engineering: Zero-ETL simplifies the data pipeline by consolidating or bypassing the extraction, transformation, and loading stages into a streamlined process. This simplification reduces complexity and accelerates data analytics and machine learning tasks, enabling faster insights for data scientists.
Real-time insights: Zero-ETL facilitates real-time data analytics by integrating extraction, transformation, and loading directly within the data platform. This integration enables instant analysis of freshly gathered data, fostering quicker decision-making and timely insights.
Key Components of Zero-ETL
Direct data integration services
Cloud providers offer dedicated services designed to automate zero-ETL integration. For instance, AWS seamlessly links Amazon Aurora with Amazon Redshift, ensuring that data inputted into Aurora is automatically synchronized with Redshift. These services manage data replication and transformation internally, thereby eliminating the need for conventional ETL processes.
Change Data Capture (CDC)
Change Data Capture (CDC) technology is crucial in zero-ETL frameworks. It monitors and captures all modifications (inserts, updates, deletes) made in source databases, swiftly replicating these changes in real-time to target systems.
Streaming data pipelines
Serverless architectures support zero-ETL by autonomously managing infrastructure and scaling resources as needed. AWS Lambda and Google Cloud Functions exemplify this approach, allowing functions to trigger in response to data events without requiring continual provisioning or oversight.
Schema-on-read technologies.
Schema-on-read provides flexibility in handling unstructured and semi-structured data like JSON and XML. Rather than specifying schemas during data writing, schemas are applied during data reading. This approach diminishes reliance on rigid structures and facilitates adaptable data analysis.
Data lakes
In a zero-ETL framework, data transformations and analyses occur directly within the data platform. This capability allows for managing various unstructured data types such as video, images, text, and numerical data within a flexible storage system like a data lake, often eliminating the need for additional intermediate processing steps.
Comparison of Zero-ETL vs. Traditional ETL
Zero-ETL and traditional ETL processes differ significantly in their approach to data integration and processing; below are some essential comparisons.
Data Virtualization: Zero-ETL leverages data virtualization technologies to simplify data integration from diverse sources. In contrast, traditional ETL processes may deem data virtualization unnecessary or difficult to implement, given the requirement to move data through transformation and loading stages.
Quality Control in Data Management: Within Zero-ETL, automated data management includes comprehensive data quality monitoring, enhancing visibility and control over quality issues. In contrast, traditional ETL methods often need help monitoring and resolving data quality issues due to their fragmented approach.
Handling Varied Data Formats: Zero-ETL utilizes cloud-based data lakes to seamlessly accommodate various data types and formats, minimizing the need for extensive architectural changes. In contrast, traditional ETL demands substantial effort in extraction and transformation to manage diverse data types and formats, limiting its flexibility.
Instant Data Processing: Zero-ETL enables instant data analysis and transformation directly within the data platform, facilitating immediate insights. In contrast, traditional ETL’s scheduled batch processing limits the ability to perform real-time data analysis effectively.
Cost-Effective Data Management: Zero-ETL typically reduces costs by requiring less infrastructure and specialized data engineering expertise. In contrast, traditional ETL tends to be more expensive, relying on additional infrastructure and skilled data professionals.
Efficient Scaling Solutions: Zero-ETL excels in speed and cost-efficiency when scaling, utilizing cloud-based architectures for swift expansion without substantial hardware investment. Conversely, traditional ETL scaling may be slower and costlier due to hardware dependencies and the necessity for extensive data movement.
Data Transfer and Mobility: Zero-ETL reduces or eliminates the necessity to relocate data, ensuring almost immediate access. In contrast, traditional ETL involves moving data through extraction, transformation, and loading phases, leading to increased latency and possible congestion points.
Zero-ETL vs ELT
Similarities: Zero-ETL and ELT (Extract, Load, Transform) optimize data analytics by postponing data transformation until it is integrated into the target system. ELT predates Zero-ETL, implementing transformation in a later phase of the data processing pipeline.
Key differences: Zero-ETL eliminates the intermediate staging phase used in ELT, resulting in lower latency and improved access to real-time data. This approach simplifies the data pipeline by reducing procedural steps and infrastructure needs.
Conclusion
Shifting away from traditional ETL stages in data analytics and machine learning signifies a significant evolution in data engineering methodologies. Adopting zero-ETL architecture offers substantial benefits, including faster processing, enhanced security, and improved scalability. Yet, this shift also introduces challenges. It could diminish the need for conventional data engineering skills, prompting data analysts, machine learning scientists, and data scientists to cultivate more sophisticated abilities in data integration. Zero-ETL prioritizes catering to the requirements of data analysts and machine learning engineers, suggesting a future where these roles gain prominence, potentially reshaping job market demands and skill requirements.
Author: Rohan Suratwale | Senior Consultant | TekLink Internaitonal LLC